Service Navigation
Search
Hail cannot be measured on the ground over a widespread comprehensive area. All the products presented are based on radar hail data, which are derived from the radar measurements with the help of algorithms. The radar hail data are compared against local ground observations such as hailstone findings or damage. The availbale radar data series from 2002 onwards is relatively short for climatological purposes. Thus statistical approaches (so-called resampling) are used to estimate rare, more severe hazards in order to make statements about extreme events that are only expected, for example, once every 50 years.
Radar data
Data from MeteoSwiss weather radars serve as the basis for the climatological calculations. In contrast to other types of measurement data, radar data are more suitable for calculating a hail climatology, as radar data cover the entire area of interest and have a high temporal and spatial resolution. This is an indispensable prerequisite for the observation of comparatively small and short-lived phenomena such as hailstorms.
The Swiss weather radar network
Since 2002, the raw data of the Swiss radar network have been available in high quality. These data cover the whole of Switzerland and neighbouring regions. Between 2002 and the end of May 2014, a total of three radars were in operation, at the sites Monte Lema in Ticino, Albis near Zurich and La Dôle near Geneva (3rd radar generation of the Swiss monitoring network). In 2011 and 2012, the three radars were completely renewed in the Rad4Alp project and equipped with the latest technological features (4th radar generation of the Swiss monitoring network). The generation change resulted in another massive improvement in data quality. Two more radars in mountain regions were added in mid-2014 and early 2016: One on the Pointe de la Plaine Morte in Valais and the other on the Weissfluh peak near Davos. The new radars provide better visibility of partially shaded mountain regions and guarantee coverage of Switzerland if one of the other radars should ever fail. In the Swiss radar network, a new 3D measurement is taken every 5 minutes and stored with a resolution of 1 km2.
Hail algorithms
Radar data are measurements of reflectivity signals at altitude, for example of raindrops or ice particles in clouds. These signals must first be converted in a complex way to obtain information on the weather at the ground level. The hail estimates are based on the difference between the height of the zero degree isotherm in the thunderstorm environment, which is obtained from the weather model, and the height of the so-called EchoTop, obtained from radar measurements. The EchoTop is related to the active core of a thundercloud. The greater the distance between the EchoTop and the zero degree isotherm, the greater the probability of hail and the expected hailstone size. MeteoSwiss has been using two main hail algorithms since 2002:
- POH (Probability of Hail), indicates the probability of hail on the ground per 1 km2 (Waldvogel et al. 1979 and Foote et al. 2005). The algorithm is based on the 45 dBZ EchoTop height, i.e. the greatest height within a vertical column at which a 45 dBZ reflectivity signal is measured by the radar, and the height of the zero degree isotherm.
- MESHS (Maximum Expected Severe Hail Size), indicates the largest possible hailstone size that could occur per 1km2 (Treloar 1998 and Joe et al. 2004). The algorithm is based, similar to POH, on the relationship between the 50 dBZ EchoTop height and the height of the zero degree isotherm. MESHS is an estimate of how large a hailstone could be that could grow if it remained in the observed thundercloud for a long time, eventually falling out of the cloud and hitting the ground. The fact that a hailstone of the size MESHS is found by someone on the ground within the square kilometre concerned is likely to be rare. Firstly, this maximum conceivable diameter is often not reached in reality, or only just. Secondly, the probability is small that a person will find the largest hailstone impacting the ground within one square kilometre before it melts. Since there are not many of the largest hailstones within the square kilometre, the probability is small that one will fall, for example, exactly on the roof of a house, and cause damage.
Both POH and MESHS are calculated over the whole of Switzerland and nearby regions in neighbouring countries with a mesh size of 1 kilometre and a temporal resolution of 5 minutes. Both data fields are available one minute after each radar measurement.
Quality check and improvement of the data basis
Although radar data are well suited for hail observations, their application to create a climatology presents some challenges.
- In the weather sector, radar data are typically used for observation and short-term forecasting (so-called nowcasting) and not for climatological purposes. This is why, for example, the temporal homogeneity of the data series is not given. Furthermore, this also means that seemingly small errors in the measurements, which are no obstacles in "normal" real-time applications and are simply filtered out by the human eye, can pose problems when aggregating data.
- In the period from 2002 to the present, the radar systems as well as the weather model, whose data are used in the hail algorithms, have been steadily improved. While these improvements increased the quality of observations and forecasts, these changes have had an impact on the long-term comparability of measurements.
Because of this, an elaborate control and preparation is indispensable before further use of the data for climatological applications. In developing the data basis for the new hail climatology of Switzerland, the effects of the technical changes on the many-year data series have been, for the first time, documented, quantified and corrected where possible. The aim is to obtain a data set that is as homogeneous as possible over time in order to be able to make robust statements about hail occurrence in the long term.
HailStoRe
The prerequisites for calculating return periods are very long measurement series. The time series of radar measurements since 2002, is short compared to typical climatological time scales which comprise at least 30 years. In addition, hail is a sporadic phenomenon, it occurs very rarely in relation to a single location, and usually lasts only a few minutes. The figure of the total sum of days with hail per location shows that, with the exception of the hotspot regions, there are only a few locations with sufficient data for a robust statistical evaluation of the extremes in the observational data. Spatial climatological evaluations are therefore often dominated by individual observed thunderstorm cells. Due to the nature of hailstorms, it can, however, be assumed that the long-term occurrence probabilities are spatially more homogeneous. On the next thunderstorm day, a thunderstorm can also take a slightly different path - even if the variability in the mountainous country of Switzerland is limited by the terrain.
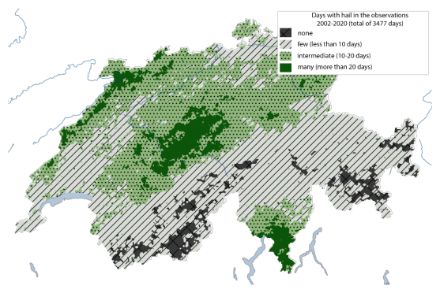
For the hazard assessment of the hail events, a resampling approach was applied. This is a statistical method in which observed events are replicated stochastically. It is used in hazard and risk analysis in the insurance and reinsurance industry, but also in impact-oriented climate research (e.g., Schwierz et al. 2010, Bloemendaal et al. 2020). The "Hail Storm Stochastic Resampler" (HailStoRe) takes into account the observed variability of hail events and estimates spatio-temporal occurrence probabilities of hail in Switzerland beyond the observations. The method comprises various modules.
Basis and concept
The new radar hail data optimised for climatological application serve as the most important basis. High-resolution details of individual hail cells are then analysed in conjunction with large-scale atmospheric conditions, derived for instance from the MeteoSwiss weather type classification. First of all, statistical models are set up of when and where hail has occurred in Switzerland in the past and under what conditions. These models make it possible, based on the large-scale weather conditions, to randomly generate hypothetical hail events in the form of synthetic radar hail fields that could plausibly occur under today's climate conditions. As a result, the potential hazard of a severe hailstorm can be simulated assuming different, stochastically generated trajectories. Furthermore, the time series simulated in this way serve as the basis for calculating the statistical return periods of the hailstone sizes.
Steps
The developed resampling model HailStoRe comprises several steps. The individual HailStoRe modules allow flexible adaptation of the prerequisites to create ensembles of plausible hail events.
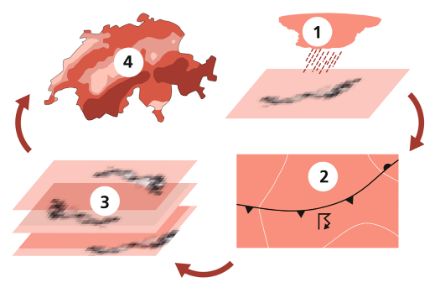
Step 1
In the first step, the radar hail data are processed and each of the approx. 40,000 observed hailstorms is coded and stored. The five-minute-resolution radar hail data are combined with trajectory information from the MeteoSwiss thunderstorms tracking algorithm (TRT-Algorithm). A storm object is created for each detected thunderstorm cell, which stores the hail footprint of the thunderstorm cell for each time step. The footprint is the spatially resolved pattern of hailstone sizes, the so-called "footprint" left by a hail cell.
Footprints
HailStoRe allows to either create stochastic event sets from the footprints of observed events or to stochastically resample the footprint objects themselves. For this purpose, the distributions of the hailstone sizes within a hailstorm are modified taking into account the spatial structures. In a first step, clusters of similar hailstorms are created based on their characteristics (track length, area, time of day) using a K-means clustering algorithm. In a second step, the distributions of the maximum hailstone sizes are described parametrically for each storm type cluster. The footprints are then replicated by stochastically transforming the value distribution of an observed footprint based on the distribution of hailstone sizes typical for this storm type. The spatial structure is retained.
Furthermore, data from the automated MeteoSwiss weather type classification and the ERA-5 reanalysis are processed for the analysis period.
Step 2
In this step, climatological patterns in the observed hail events are linked to environmental conditions (weather conditions) and a resampling model is created. In this step, we determine which variables of the environmental conditions are used for prediction. It is possible to create a model based only on the large-scale weather situations, or to include other factors from the reanalysis that contribute to the development of thunderstorm situations in the initial weather situations. As a second factor, the regions are determined in which similar hail patterns are to be expected on the basis of previous observations. Typically, a distinction is made between the Swiss Plateau, the southern side of the Alps, the Alpine region with less hail and the Jura region. Once the predictors have been determined, statistical models are created that describe the hail conditions as best as possible. In order to represent the convective activity over Switzerland, the distribution of the number of hail cells formed is mapped using a negative binomial model with zero-inflation. The parameters are adjusted for each weather situation. The typical regions of origin are also recorded with the aid of 2D kernel density maps, which show the regions in which hail cells are more or less likely to form given the weather situation.
Step 3
In the third step, stochastic event sets, i.e. plausible hypothetical events, are created and validated using longer time series. The time series of the weather conditions for which the hail frequencies were examined during the observation period serve as the initial data. These data contain the weather of several decades and serve as the starting point for the resampling. In order to obtain a long series of possible data, one of the available years is randomly selected a thousand times per simulation. A plausible hail scenario is now modelled for each day of each year. In each case, a day is generated randomly (stochastically) within the parametrically described conditions for the respective region and weather situation.
The following steps are carried out for each day of the initial time series:
- Based on the initial weather situation, a number of hailstorms over Switzerland and their points of origin are generated.
- For each initialisation, a footprint is randomly selected. The selection is made from all footprints that occurred under these conditions in the respective region of origin. The population of footprints can be restricted to the observed hailstorms or the use of statistically multiplied footprints can be allowed (see step 1). The footprint is located at the initialisation point.
- For each day, the daily maxima of the hailstone sizes are stored as a grid.
- The statistics of the modelled time series are compared with the statistics of the observations. The number of hail days, the annual cycle, the spatial distribution of the hailstorms in the regions of origin and the hailstone sizes are described quantitatively.
Step 4
In the fourth step, the frequencies of occurring hailstone sizes are analysed and exceedance probabilities are determined. Based on the very long data series plausibly simulated under today's climate conditions, the frequency of occurrence of hail events with different hailstone sizes is determined. The results thereof are shown in the maps of return values.